

Semantic Segmentation using U-Net
U-Net
U-Net is a U-shaped encoder-decoder network architecture, which consists of four encoder blocks and four decoder blocks that are connected via bridges with skip connections. It is one of the most popularly used approaches in any semantic segmentation task. It was originally introduced by Olaf Ronneberger through the publication “U-Net: Convolutional Networks for Biomedical Image Segmentation”. It is built upon fully convolutional neural network that is designed to learn from fewer training samples.
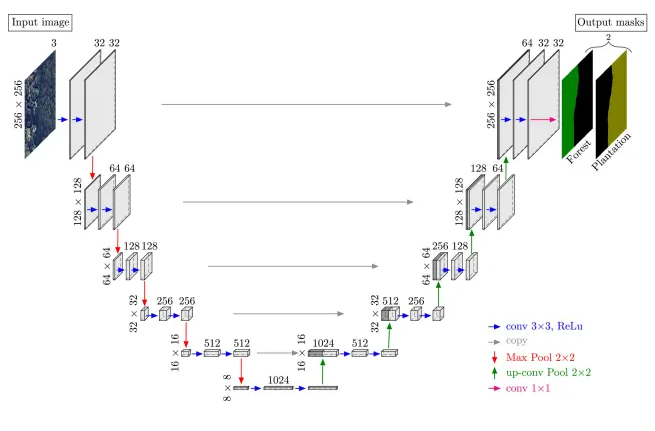
It has three main componets namely encoder network, decoder network and skip connections. The encoder network (contracting path) half the spatial dimensions and double the number of feature channels at each encoder block while the decoder network double the spatial dimensions and half the number of of feature channels. The skip connections connect output of encoder block with corresponding input of decoder block.
Encoder Network
Encoder Network acts as the feature extractor and learn an abstract representation of the input image through a sequence of the encoder blocks. Each encoder block consists of $3 \times 3$ convolutions where each convolution is followed by a ReLU (Rectified Linear Unit) activation function. The ReLU function introduces non-linearity into the network, which helps in the better generalization of the training data. The output of ReLU acts as a skip connection for the corresponding decoder block.
Next follows a $2 \times 2$ max-pooling, where the spatial dimensions of the feature maps are reduced by half. This reduces the computational cost by decreasing the number of trainable parameters.
Skip Connection
These skip connections provide additional information that helps the decoder generate better semantic features. They also act as a shortcut connection that helps the indirect flow of gradients to the earlier layers without any degradation.
The bridge connects the encoder and decoder network and completes the flow of information.
Decoder Network
It is used to take the abstract representation and generate a semantic segmentation mask. The decoder block starts with $2 \times 2$ transpose convolution. Next, it is concatenated with the corresponding skip connection feature map from the encoder block. These skip connections provide features from earlier layers that are sometimes lost due to the depth of the network. The output of the last decoder passes through $1 \times 1$ convolution with sigmoid activation. The sigmoid activation function gives the segmenation mask representing the pixel-wise classification.
It is prefered to use batch normalization in between the convolution layer and the ReLU activation function. It reduces internal covariance shift and makes the network more stable while training. Sometimes, the dropout is used after ReLU. It forces the network to learn different representation by dropping out some randomly selected neurons. It helps the network to become less dependent upon certain neuron. This in turn helps the network to better generalize and prevent it from overfitting.
Semantic Segmentation for Self Driving Cars
This dataset provides data images and labeled semantic segmentations captured via CARLA self-driving car simulator. The data was generated as part of the Lyft Udacity Challenge . This dataset can be used to train ML algorithms to identify semantic segmentation of cars, roads etc in an image. The data has $5$ sets of $1000$ images and corresponding labels. There are $23$ different labels ranging from road, roadlines, sidewalk to building, pedestrians, fences.
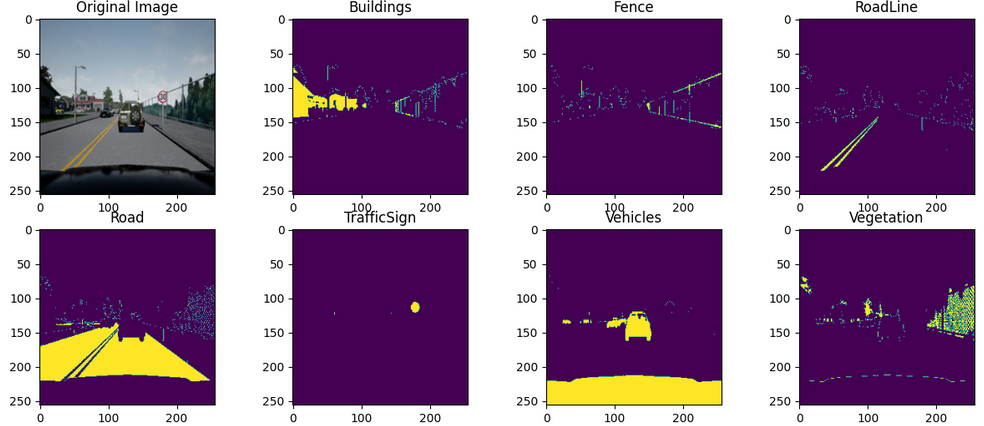
For our training, we chose the first $13$ labels. All the images and labels were resized to $256 \times 256$ to avoid any tensor mismatch while training. The train-validation-test split was $0.6$, $0.2$ and $0.2$. Learning rate was chosen to be $0.001$ for Adam optimizer. The performance of the network was optimized with the help of Dice Loss which is defined as
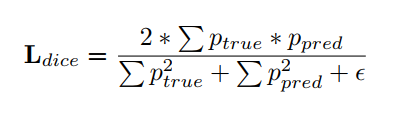
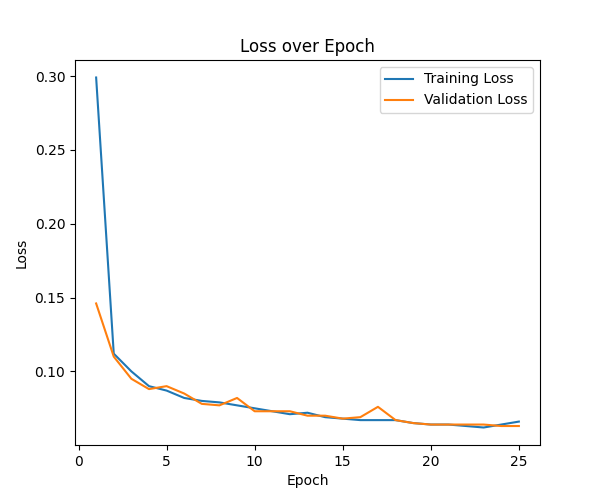
where $p_{true}, p_{pred}$ are ground truth and predicted labels. $\epsilon$ is small number $\leq 1$. The network was trained over 100 epochs. Other network parameters were {batch_size=8, device=gpu}.The performance of network for the first 25 epoch is given as
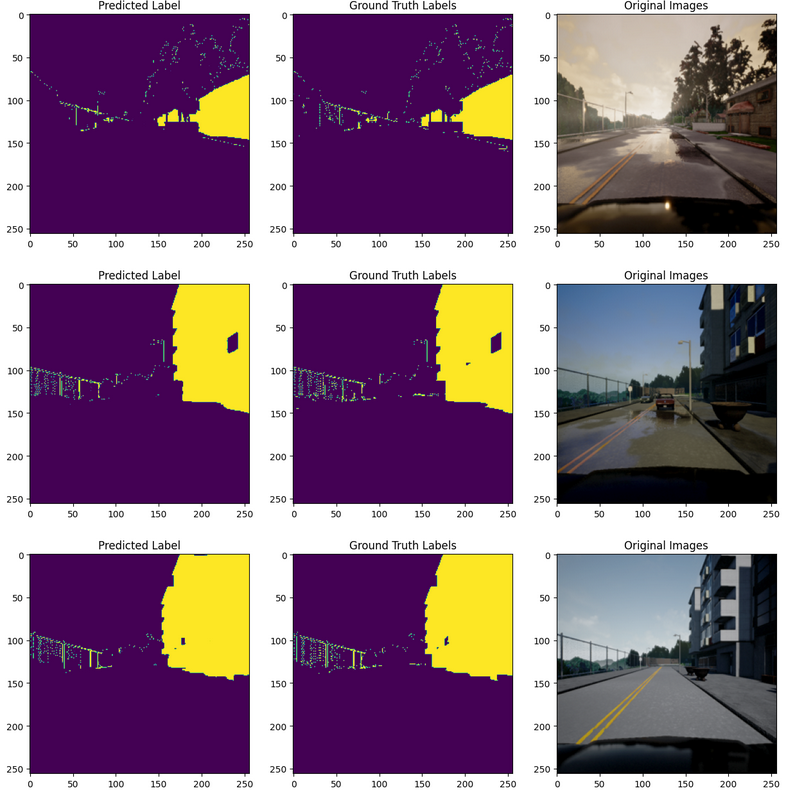
Some predicted results for buildings with their ground truth is as follow.
Conclusion
In all, U-Net works exceptionally for basic semantic segmentation tasks even when we have fewer training samples. Improved version to original U-Net like U-Net++, Dense-UNet have been introduced for specific tasks in medical and aerial imaging.
References
[1] U-Net: Convolutional Networks for Biomedical Image Segmentation
[2] What is UNET?
