

Replication & Consistency in Cassandra
Before we start with the consistency, replication and read-write operation in Cassandra, let’s first familiarize ourselves with what Cassandra is and its architecture. Already know about cassandra, let’s get started.
Consistency
The Cassandra consistency level is defined as the minimum number of Cassandra nodes that must acknowledge a read or write operation before the operation can be considered successful. Different consistency levels can be assigned to different Edge keyspaces. When connecting to Cassandra for read and write operations, Message Processor and Management Server nodes typically use the Cassandra value of LOCAL_QUORUM to specify the consistency level for a keyspace. However, some keyspaces are defined to use a consistency level of one. The calculation of the value of LOCAL_QUORUM for a data center is:
LOCAL_QUORUM = (replication_factor/2) + 1
As described above, the default replication factor for an Edge production environment with three Cassandra nodes is three. Therefore, the default value of LOCAL_QUORUM = (3/2) +1 = 2 (the value is rounded down to an integer). With LOCAL_QUORUM = 2, at least two of the three Cassandra nodes in the data center must respond to a read/write operation for the operation to succeed. For a three node Cassandra cluster, the cluster could therefore tolerate one node being down per data center.
Data replication
Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed. The total number of replicas across the cluster is referred to as the replication factor. A replication factor of 1 means that there is only one copy of each row in the cluster. If the node containing the row goes down, the row cannot be retrieved. A replication factor of 2 means two copies of each row, where each copy is on a different node. All replicas are equally important; there is no primary or master replica. As a general rule, the replication factor should not exceed the number of nodes in the cluster. However, you can increase the replication factor and then add the desired number of nodes later. Two replication strategies are available:
SimpleStrategy:
Use only for a single datacenter and one rack. If you ever intend more than one datacenter, use the NetworkTopologyStrategy. NetworkTopologyStrategy: Highly recommended for most deployments because it is much easier to expand to multiple datacenters when required by future expansion. SimpleStrategy Use only for a single datacenter and one rack. SimpleStrategy places the first replica on a node determined by the partitioner. Additional replicas are placed on the next nodes clockwise in the ring without considering topology (rack or datacenter location).
NetworkTopologyStrategy
Use NetworkTopologyStrategy when you have (or plan to have) your cluster deployed across multiple datacenters. This strategy specifies how many replicas you want in each datacenter. NetworkTopologyStrategy places replicas in the same datacenter by walking the ring clockwise until reaching the first node in another rack. NetworkTopologyStrategy attempts to place replicas on distinct racks because nodes in the same rack (or similar physical grouping) often fail at the same time due to power, cooling, or network issues.
How are consistent read and write operations handled?
Consistency refers to how up-to-date and synchronized all replicas of a row of Cassandra data are at any given moment. Ongoing repair operations in Cassandra ensure that all replicas of a row will eventually be consistent. Cassandra is an AP system according to the CAP theorem, providing high availability and partition tolerance. Cassandra does have flexibility in its configuration, though, and can perform more like a CP (consistent and partition tolerant) system according to the CAP theorem, depending on the application requirements. Two consistency features are tunable consistency and linearizable consistency.
Tunable consistency
To ensure that Cassandra can provide the proper levels of consistency for its reads and writes, Cassandra extends the concept of eventual consistency by offering tunable consistency. You can tune Cassandra’s consistency level per-operation, or set it globally for a cluster or datacenter. You can vary the consistency for individual read or write operations so that the data returned is more or less consistent, as required by the client application. This allows you to make Cassandra act more like a CP (consistent and partition tolerant) or AP (highly available and partition tolerant) system according to the CAP theorem, depending on the application requirements. Note: It is not possible to “tune” Cassandra into a completely CA system. There is a tradeoff between operation latency and consistency: higher consistency incurs higher latency, lower consistency permits lower latency. You can control latency by tuning consistency. The consistency level determines the number of replicas that need to acknowledge the read or write operation success to the client application.
For read operations, the read consistency level specifies how many replicas must respond to a read request before returning data to the client application. If a read operation reveals inconsistency among replicas, Cassandra initiates a read repair to update the inconsistent data.
For write operations, the write consistency level specifies how many replicas must respond to a write request before the write is considered successful. Even at low consistency levels, Cassandra writes to all replicas of the partition key, including replicas in other datacenters. The write consistency level just specifies when the coordinator can report to the client application that the write operation is considered completed. Write operations will use hinted handoffs to ensure the writes are completed when replicas are down or otherwise not responsive to the write request. The choices made depend on the client application’s needs, and Cassandra provides maximum flexibility for application design.
Linearizable consistency
In ACID terms, linearizable consistency (or serial consistency) is a serial (immediate) isolation level for lightweight transactions. Cassandra does not employ traditional mechanisms like locking or transactional dependencies when concurrently updating multiple rows or tables. However, some operations must be performed in sequence and not interrupted by other operations. For example, duplications or overwrites in user account creation can have serious consequences. Situations like race conditions (two clients updating the same record) can introduce inconsistency across replicas. Writing with high consistency does nothing to reduce this. You can apply linearizable consistency to a unique identifier, like the userID or email address, although it is not required for all aspects of the user’s account. Serial operations for these elements can be implemented in Cassandra with the Paxos consensus protocol, which uses a quorum-based algorithm.
Calculating consistency
Reliability of read and write operations depends on the consistency used to verify the operation. Strong consistency can be guaranteed when the following condition is true:
R + W > N
where
R is the consistency level of read operations W is the consistency level of write operations N is the number of replicas
If the replication factor is 3, then the consistency level of the reads and writes combined must be at least 4. For example, read operations using 2 out of 3 replicas to verify the value, and write operations using 2 out of 3 replicas to verify the value will result in strong consistency. If fast write operations are required, but strong consistency is still desired, the write consistency level is lowered to 1, but now read operations have to verify a matched value on all 3 replicas. Writes will be fast, but reads will be slower. Eventual consistency occurs if the following condition is true: R + W =< N where R is the consistency level of read operations W is the consistency level of write operations N is the number of replicas If the replication factor is 3, then the consistency level of the reads and writes combined are 3 or less.
For example, read operations using QUORUM (2 out of 3 replicas) to verify the value, and write operations using ONE (1 out of 3 replicas) to do fast writes will result in eventual consistency. All replicas will receive the data, but read operations are more vulnerable to selecting data before all replicas write the data.
How are write requests accomplished?
The coordinator sends a write request to all replicas that own the row being written. As long as all replica nodes are up and available, they will get the write regardless of the consistency level specified by the client. The write consistency level determines how many replica nodes must respond with a success acknowledgment in order for the write to be considered successful. Success means that the data was written to the commit log and the memtable as described in how data is written.
The coordinator node forwards the write to replicas of that row, and responds to the client once it receives write acknowledgments from the number of nodes specified by the consistency level. Exceptions:
If the coordinator cannot write to enough replicas to meet the requested consistency level, it throws an Unavailable Exception and does not perform any writes.
If there are enough replicas available but the required writes don’t finish within the timeout window, the coordinator throws a Timeout Exception.
For example, in a single datacenter 10-node cluster with a replication factor of 3, an incoming write will go to all 3 nodes that own the requested row. If the write consistency level specified by the client is ONE, the first node to complete the write responds back to the coordinator, which then proxies the success message back to the client. A consistency level of ONE means that it is possible that 2 of the 3 replicas can miss the write if they happen to be down at the time the request is made. If a replica misses a write, the row is made consistent later using one of the built-in repair mechanisms: hinted handoff, read repair, or anti-entropy node repair.
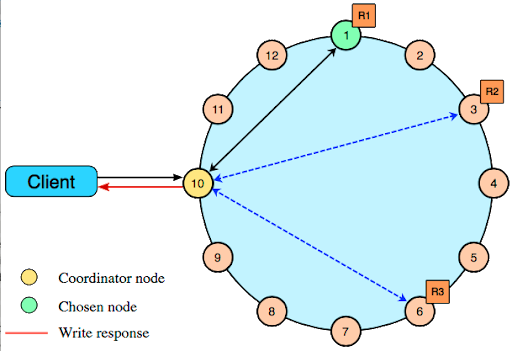
How are read requests accomplished?
There are three types of read requests that a coordinator can send to a replica:
1) A direct read request
2) A digest request
3) A background read repair request
In a direct read request, the coordinator node contacts one replica node. Then the coordinator sends a digest request to a number of replicas determined by the consistency level specified by the client. The digest request checks the data in the replica node to make sure it is up to date. Then the coordinator sends a digest request to all remaining replicas. If any replica nodes have out of date data, a background read repair request is sent. Read repair requests ensure that the requested row is made consistent on all replicas involved in a read query.
For a digest request the coordinator first contacts the replicas specified by the consistency level. The coordinator sends these requests to the replicas that currently respond the fastest. The contacted nodes respond with a digest of the requested data; if multiple nodes are contacted, the rows from each replica are compared in memory for consistency. If they are not consistent, the replica having the most recent data (based on the timestamp) is used by the coordinator to forward the result back to the client. To ensure that all replicas have the most recent version of the data, read repair is carried out to update out-of-date replicas.
Conclusion
You have broad the knowlege on consistency, replication in Cassandra.
Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. To ensure that Cassandra can provide the proper levels of consistency for its reads and writes, You can vary the consistency for individual read or write operations so that the data returned is more or less consistent.
